版权声明:
尊重知识产权,严厉打击非法采集。
今天同事向我咨询一个SQL问题,假如,有如下数据表,需求是只消除连续的重复行。
如下数据(表名为 Hooyes, id 是连续的 ),
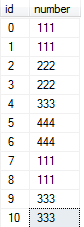
id 0,1 的number (111) 连续的重复了,只保留一行,id 7,8 的number(111) 也连续重复了,也只保留一行。依此类推。 要求得到的结果如下:
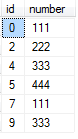
那么如何实现呢?我思考了一下,给出了如下答案:
SELECT t2.id ,
t2.number
FROM ( SELECT id = id + 1 ,
number
FROM hooyes
UNION
SELECT 0 ,
0
) AS t1
INNER JOIN hooyes t2 ON t2.id = t1.id
AND t1.number != t2.number
从SQL中,应该能看出来我的思路,就是把原数据表 number 列,错一位,id 不错位,然后再通过id 关联,(这个hooyes 表 id 是连续的,如果ID不是连续的,那个可以使用为 row_number 来进行错位)
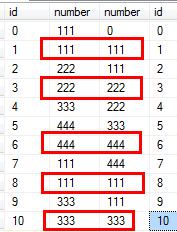
判断 number 不相等的列,便可以筛选出来了。
$ welcome to hooyes.net
[INFO] ------------------------------o-
[INFO] Author : HOOYES
[INFO] Site : https://hooyes.net
[INFO] Page : https://hooyes.net/p/sql-remove-duplicate
[INFO] Last build : 2025-11-22 11:31:45 +0000
[INFO] -0------------------------------